Корневой узел. Двоичное дерево. Операции с двоичными деревьями
Древовидной структурой данных называется конечное множество элементов-узлов, между которыми существуют отношения – связь исходного и порожденного.
Если использовать рекурсивное определение, предложенное Н. Виртом, то древовидная структура данных с базовым типом t – это либо пустая структура, либо узел типа t, с которым связано конечное множество древовидных структур с базовым типом t, называемых поддеревьями.
Если узел у находится непосредственно под узлом х, то узел у называется непосредственным потомком узла х, а х – непосредственным предком узла у, т. е., если узел х находится на i-ом уровне, то соответственно узел у находится на (i + 1) – ом уровне.
Максимальный уровень узла дерева называется высотой или глубиной дерева. Предка не имеет только один узел дерева – его корень.
Узлы дерева, у которых не имеется потомков, называются терминальными узлами (или листами дерева). Все остальные узлы называются внутренними узлами. Количество непосредственных потомков узла определяет степень этого узла, а максимально возможная степень узла в данном дереве определяет степень дерева.
Предков и потомков нельзя поменять местами, т. е. связь исходного и порожденного действует только в одном направлении.
Если пройти от корня дерева к некоторому конкретному узлу, то количество ветвей дерева, которое при этом будет пройдено, называется длиной пути для этого узла. Если все ветви (узлы) у дерева упорядочены, то дерево называется упорядоченным.
Частным случаем древовидных структур являются бинарные деревья. Это деревья, в которых каждый потомок имеет не более двух потомков, называемых левым и правым поддеревьями. Таким образом, бинарное дерево – это древовидная структура, степень которой равна двум.
Упорядоченность бинарного дерева определяется по следующему правилу: каждому узлу соответствует свое ключевое поле, и для каждого узла значение ключа больше всех ключей в его левом поддереве и меньше всех ключей в его правом поддереве.
Дерево, степень которого больше двух, называется сильноветвящимся.
2. Операции над деревьями
I. Построение дереваПриведем алгоритм построения упорядоченного дерева.
1. Если дерево пусто, то данные переносятся в корень дерева. Если же дерево не пусто, то осуществляется спуск по одной из его ветвей таким образом, чтобы упорядоченность дерева не нарушалась. В результате новый узел становится очередным листом дерева.
2. Чтобы добавить узел в уже существующее дерево, можно воспользоваться вышеприведенным алгоритмом.
3. При удалении узла из дерева следует быть внимательным. Если удаляемый узел является листом, или же имеет только одного потомка, то операция проста. Если же удаляемый узел имеет двух потомков, то необходимо будет найти узел среди его потомков, который можно будет поставить на его место. Это нужно в силу требования упорядоченности дерева.
Можно поступить таким образом: поменять удаляемый узел местами с узлом, имеющем самое большое значение ключа в левом поддереве, или с узлом, имеющем самое малое значение ключа в правом поддереве, а затем удалить искомый узел как лист.
II. Поиск узла с заданным значением ключевого поляПри осуществлении этой операции необходимо совершить обход дерева. Необходимо учитывать различные формы записи дерева: префиксную, инфиксную и постфиксную.
Возникает вопрос: каким образом представить узлы дерева, чтобы было наиболее удобно работать с ними? Можно представлять дерево с помощью массива, где каждый узел описывается величиной комбинированного типа, у которой информационное поле символьного типа и два поля ссылочного типа. Но это не совсем удобно, так как деревья имеют большое количество узлов, заранее не определенное. Поэтому лучше всего при описании дерева использовать динамические переменные. Тогда каждый узел представляется величиной одного типа, которая содержит описание заданного количества информационных полей, а количество соответствующих полей должно быть равно степени дерева. Логично отсутствие потомков определять ссьшкой nil. Тогда на языке Pascal описание бинарного дерева может выглядеть следующим образом:
TYPE TreeLink = ^Tree;
Inf: <тип данных>;
Left, Right: TreeLink;
3. Примеры реализации операций
1. Построить дерево из n узлов минимальной высоты, или идеально сбалансированное дерево (количество узлов левого и правого поддеревьев такого дерева должны отличаться не более чем на единицу).
Рекурсивный алгоритм построения:
1) первый узел берется в качестве корня дерева.
2) тем же способом строится левое поддерево из nl узлов.
3) тем же способом строится правое поддерево из nr узлов;
nr = n – nl – 1. В качестве информационного поля будем брать номера узлов, вводимые с клавиатуры. Рекурсивная функция, реализующая данное построение, будет выглядеть следующим образом:
Function Tree(n: Byte) : TreeLink;
Var t: TreeLink; nl,nr,x: Byte;
If n = 0 then Tree:= nil
nr = n – nl – 1;
writeln("Введите номер вершины ");
t^.left:= Tree(nl);
t^.right:= Tree(nr);
2. В бинарном упорядоченном дереве найти узел с заданным значением ключевого поля. Если такого элемента в дереве нет, то добавить его в дерево.
Procedure Search(x: Byte; var t: TreeLink);
Else if x < t^.inf then
Search(x, t^.left)
Else if x > t^.inf then
Search(x, t^.right)
{обработка найденного элемента}
3. Написать процедуры обхода дерева в прямом, симметричном и обратном порядке соответственно.
3.1. Procedure Preorder(t: TreeLink);
If t <> nil then
Writeln(t^.inf);
Preorder(t^.left);
Preorder(t^.right);
3.2. Procedure Inorder(t: TreeLink);
If t <> nil then
Inorder(t^.left);
Writeln(t^.inf);
Inorder(t^.right);
3.3. Procedure Postorder(t: TreeLink);
If t <> nil then
Postorder(t^.left);
Postorder(t^.right);
Writeln(t^.inf);
4. В бинарном упорядоченном дереве удалить узел с заданным значением ключевого поля.
Опишем рекурсивную процедуру, которая будет учитывать наличие требуемого элемента в дереве и количество потомков этого узла. Если удаляемый узел имеет двух потомков, то он будет заменен самым большим значением ключа в его левом поддереве, и только после этого он будет окончательно удален.
Procedure Delete1(x: Byte; var t: TreeLink);
Var p: TreeLink;
Procedure Delete2(var q: TreeLink);
If q^.right <> nil then Delete2(q^.right)
p^.inf:= q^.inf;
Writeln("искомого элемента нет")
Else if x < t^.inf then
Delete1(x, t^.left)
Else if x > t^.inf then
Delete1(x, t^.right)
If p^.left = nil then
If p^.right = nil then
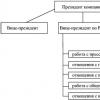
Древовидная модель оказывается довольно эффективной для представления динамических данных с целью быстрого поиска информации .Деревья являются одними из наиболее широко распространенных структур данных в информатике и программировании, которые представляют собой иерархические структуры в виде набора связанных узлов.
– это структура данных , представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов ( рис. 31.1). Каждый элемент дерева называется вершиной (узлом) дерева . Вершины дерева соединены направленными дугами, которые называют ветвями дерева . Начальный узел дерева называют корнем дерева , ему соответствует нулевой уровень. Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви.
Каждое дерево обладает следующими свойствами:
- существует узел, в который не входит ни одной дуги (корень);
- в каждую вершину, кроме корня, входит одна дуга.
Деревья особенно часто используют на практике при изображении различных иерархий. Например, популярны генеалогические деревья.
Рис. 31.1.Все вершины, в которые входят ветви, исходящие из одной общей вершины, называются потомками , а сама вершина – предком . Для каждого предка может быть выделено несколько. Уровень потомка на единицу превосходит уровень его предка. Корень дерева не имеет предка, а листья дерева не имеют потомков.
Высота (глубина) дерева определяется количеством уровней, на которых располагаются его вершины. Высота пустого дерева равна нулю, высота дерева из одного корня – единице. На первом уровне дерева может быть только одна вершина – корень дерева , на втором – потомки корня дерева, на третьем – потомки потомков корня дерева и т.д.
Поддерево – часть древообразной структуры данных, которая может быть представлена в виде отдельного дерева.
Степенью вершины в дереве называется количество дуг, которое из нее выходит. Степень дерева равна максимальной степени вершины, входящей в дерево . При этом листьями в дереве являются вершины, имеющие степень нуль. По величине степени дерева различают два типа деревьев:
- двоичные – степень дерева не более двух;
- сильноветвящиеся – степень дерева произвольная.
Упорядоченное дерево – это дерево , у которого ветви, исходящие из каждой вершины, упорядочены по определенному критерию.
Деревья являются рекурсивными структурами, так как каждое поддерево также является деревом. Таким образом, дерево можно определить как рекурсивную структуру, в которой каждый элемент является:
- либо пустой структурой;
- либо элементом, с которым связано конечное число поддеревьев.
Действия с рекурсивными структурами удобнее всего описываются с помощью рекурсивных алгоритмов.
Списочное представление деревьев основано на элементах, соответствующих вершинам дерева. Каждый элемент имеет поле данных и два поля указателей: указатель на начало списка потомков вершины и указатель на следующий элемент в списке потомков текущего уровня. При таком способе представления дерева обязательно следует сохранять указатель на вершину, являющуюся корнем дерева .
Для того, чтобы выполнить определенную операцию над всеми вершинами дерева необходимо все его вершины просмотреть. Такая задача называется обходом дерева .
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая вершина встречается только один раз.
При обходе все вершины дерева должны посещаться в определенном порядке. Существует несколько способов обхода всех вершин дерева. Выделим три наиболее часто используемых способа обхода дерева ( рис. 31.2):
- прямой;
- симметричный;
- обратный.
Рис. 31.2.Существует большое многообразие древовидных структур данных. Выделим самые распространенные из них: бинарные (двоичные) деревья, красно-черные деревья, В-деревья, АВЛ-деревья , матричные деревья, смешанные деревья и т.д.
Бинарные деревья
Бинарные деревья являются деревьями со степенью не более двух.
Бинарное (двоичное) дерево – это динамическая структура данных , представляющее собой дерево , в котором каждая вершина имеет не более двух потомков ( рис. 31.3). Таким образом, бинарное дерево состоит из элементов, каждый из которых содержит информационное поле и не более двух ссылок на различные бинарные поддеревья. На каждый элемент дерева имеется ровно одна ссылка .
Рис. 31.3.Каждая вершина бинарного дерева является структурой, состоящей из четырех видов полей. Содержимым этих полей будут соответственно:
- информационное поле (ключ вершины);
- служебное поле (их может быть несколько или ни одного);
- указатель на левое поддерево ;
- указатель на правое поддерево .
По степени вершин бинарные деревья делятся на ( рис. 31.4):
Рис. 31.4.
- строгие – вершины дерева имеют степень ноль (у листьев) или два (у узлов);
- нестрогие – вершины дерева имеют степень ноль (у листьев), один или два (у узлов).
Абстрактное бинарное дерево
Лекция Деревья
Деревья (trees) используются для представления отношения. Все деревья являются иерархическими по своей сути. Интуитивное значение этого термина состоит в том, что между узлами дерева существует отношение "родительский-дочерний". Если ребро соединяет узел n и узел т, причем узел п находится выше узла т, то узел n считается родителем (parent) узла т, а узел т - его дочерним узлом (child) . В дереве, изображенном на рис. 10.1, узлы В и С являются дочерними по отношению к узлу А. Дочерние узлы, имеющие одного и того же родителя, - например, узлы В и С - называются братьями (siblings) . Каждый узел дерева имеет по крайней мере одного родителя, причем в дереве существует только один узел, не имеющий предков. Такой узел называется корнем дерева (root) . На рис. 10.1 корнем является узел А. Узел, у которого нет дочерних узлов, называется листом дерева (leaf). Листьями дерева, изображенного на рис. 10.1, являются узлы С, D, Е и F.
Рис. 10.1. Дерево общего в
Отношения между родительским и дочерним узлом с абстрактной точки зрения является отношением между предком (ancestor) и потомком (descendant). На рис. 10.1 узел А является предком узла Д следовательно, узел D является потомком узла А. Не все узлы могут быть связаны отношениями "предок-потомок": узлы В и С, например, не связаны родственными отношениями. Однако корень любого дерева является предком каждого его узла. Поддеревом (subtree) называется любой узел дерева со всеми его потомками. Поддеревом узла п является поддерево, корнем которого является узел n. Например, на рис. 10.2 показано поддерево дерева, изображенного на рис. 10.1. Корнем этого поддерева является узел В, а само поддерево является поддеревом узла А.
С формальной точки зрения, дерево общего вида (general tree) T представляет собой множество, состоящее из одного или нескольких узлов, принадлежащих непересекающимся подмножествам, указанным ниже.
Отдельный узел r, корень.
Множество поддеревьев корня r.
Бинарное дерево (binary tree) - это множество узлов Т, таких что
Множество Т пусто, или
Множество Т распадается на три непересекающихся подмножества:
Отдельный корень r, корень;
Два возможно пустых поддерева бинарного дерева, которые называются левым и правым поддеревьями (leaf and right subtrees) корня r, соответственно.
В качестве иллюстрации использования бинарных деревьев для представления данных в иерархическом виде рассмотрим рис. 10.4. На этом рисунке бинарные деревья представляют алгебраические выражения, содержащие бинарные операторы +, -, * и /. Для представления выражения а-b оператор помещается в корневой узел, а операнды а и b- в его левый и правый дочерние узлы, соответственно (рис. 10.4). На рис. 10.4, б представлено выражение a-b/с, где поддерево представляет подвыражение b/с. Аналогичная ситуация показана на рис. 10.4, в, где изображено выражение (а-b)*с. В узлах этих деревьев хранятся операнды выражений, а в остальных узлах - операторы. Скобки в этих деревьях не представлены. Бинарное дерево создает иерархию операций, т.е. дерево однозначно определяет порядок вычисления выражения.
Рис. 10.4. Бинарные деревья, представляющие алгебраические выражения
Бинарное дерево поиска - это бинарное дерево, некоторым образом упорядоченное в соответствии со значениями, содержащимися в его узлах. Каждый узел п бинарного дерева поиска обладает следующими тремя свойствами:
Значение узла п больше всех значений, содержащихся в левом поддереве TL.
Значение узла п меньше всех значений, содержащихся в правом поддереве ТR.
Деревья TL и ТR являются деревьями бинарного поиска.
На рис. 10.5 показан пример бинарного дерева поиска. Как следует из его названия, это дерево обеспечивает возможности поиска конкретного элемента. Позднее мы рассмотрим эту структуру данных более подробно.
Высота деревьев. Деревья могут иметь разную форму. Например, хотя деревья, изображенные на рис. 10.6, состоят из одинаковых узлов, они имеют совершенно разную структуру. Каждое из этих деревьев содержит семь узлов, но некоторые деревья "выше" других. Высота (height) дерева - это количество узлов, расположенных на самом длинном пути от корня к листу. Например, высота деревьев, показанных на рис. 10.6, равна 3, 5 и 7, соответственно. Интуитивное представление о высоте деревьев может привести к заключению, что их высота равна 2, 4 и 6, соответственно. Действительно, многие авторы используют именно интуитивное определение высоты дерева (подсчитывая количество ребер на самом длинном пути от корня до дерева. - Прим. ред.). Однако принятое нами определение позволяет более четко формулировать многие алгоритмы и свойства деревьев.
Полное, совершенное и сбалансированное дерево. В полном бинарном дереве(full binary tree), имеющем высоту h, все узлы, расположенные на уровнях, меньших уровня h, имеют по два дочерних узла. На рис. 10.7 представлено полное бинарное дерево, имеющее высоту, равную 3. Каждый узел полного бинарного дерева имеет левое и правое поддерево, имеющие одинаковую высоту . Среди всех бинарных деревьев, высота которых равна h, полное бинарное дерево имеет максимально возможное количество листьев, и все они расположены на уровне h. Проще говоря, в полном бинарном дереве нет пропущенных узлов.
Доказывая свойства полных бинарных деревьев, подсчитывая количество их узлов, удобно пользоваться рекурсивным определением.
Если дерево Т пусто, то оно является полным бинарным деревом, имеющим
высоту, равную 0.
Если дерево T не пусто, и его высота равна h > 0, то дерево T является полным бинарным деревом, если поддеревья его корня являются полными бинарными деревьями, имеющими высоту h-1.
Это определение хорошо отражает рекурсивную природу бинарного дерева.
Совершенное бинарное дерево (complete binary tree), имеющее высоту h, - это бинарное дерево, которое является полным вплоть до уровня h-1, а уровень h заполнен слева направо так, как показано на рис. 10.8.
Рис. 10.8. Совершенное бинарное дерево
Очевидно, что полное бинарное дерево является совершенным.
Бинарное дерево называется сбалансированным по высоте (height balanced), или просто сбалансированным (balanced), если высота правого поддерева любого его узла отличается от высоты левого поддерева не больше, чем на 1. Бинарные деревья, изображенные на рис. 10.8 и 10.6, а, являются сбалансированными, а деревья, представленные на рис. 10.6, б и 10.6, в - нет. Совершенное бинарное дерево является сбалансированным. Итак, повторим кратко введенные понятия.
Абстрактное бинарное дерево
B бинарном дереве существует несколько способов обхода. Стандартными являются три порядка обхода дерева: прямой, симметричный и обратный. Все они описываются в следующем разделе. Над абстрактным бинарным деревом выполняются следующие операции.
Двоичные деревья поиска или бинарные деревья(binary tree) — это структура данных, состоящая из:
- одного единственного корневого узла, который не имеет родителей;
- остальных узлов, которые имеют одного единственного родителя и не более двух потомков.
Каждый узел дерева может быть корневым узлом для одного из своих поддеревьев(subtree) . Родительский узел — это узел, который имеет одного или двух потомков. Тот узел, который не имеет потомков, называется листом или листовым узлом . Двоичные деревья поиска названы так не просто потому что каждый узел дерева может иметь два потомка. Ключ левого потомка данного узла должен быть меньше, чем значение, которое хранит этот узел. Ключ правого потомка должен быть больше значения, которое хранится в родительском узле (см.рисунок).
В общем случае структуру для хранения узла можно представить следующим образом(на языке С):
typedef struct _Node
int data ;
struct Node * parent ;
struct Node * left ;
struct Node * right ;
} Node ;
Структура, представляющая узел хранит сами данные(поле data ) и три указателя — на родительский узел, левого и правого потомков. У корневого узла дерева поле parent будет равно NULL . Сохранение ссылки на родительский узел на самом деле необязательно. Но в некоторых случаях используется.
Еще раз взгляните на рисунок выше.
Корневой узел содержит в себе значение 27. Значение, которое хранит его левый потомок должно быть меньше, чем значение родительского узла. Мы видим там число 14 (14 < 27). Правый же потомок хранит больше значение(35 > 27) и так далее. Временная сложность процедуры поиска в двоичном дереве поиска оценивается как O(logN) . Допустим, что нам нужно найти вершину с ключом, равным 31.
Для того, чтобы найти этот узел, мы сначала сравниваем его со значением в корне. Корень хранит число 27, которое не является искомым элементом(21 != 27). При этом значение искомого элемента больше(31 > 27), чем значение, хранимое в текущем узле, а это значит, что поиск следует продолжить в правом поддереве. Теперь мы пришли в узел со значением 35. Это также не то, что мы искали, поэтому мы двигаемся дальше, а именно в левое поддерево(так как 31 < 35).
В итоге мы приходим в узел со значением 31, а это именно тот элемент, который мы искали. Возможно вся эта процедура уже вам напомнила обычный двоичный поиск в упорядоченном массиве. Это действительно так. Чем же тогда такое дерево лучше обычного массива? Помимо того же преимущества в скорости поиска, бинарное дерево упрощает процедуру вставки нового элемента в середину последовательности, так как в случае с бинарным деревом нам нужно лишь поменять несколько ссылок.
Но на самом деле у двоичного дерева есть один недостаток. И в некоторых ситуациях он может оказаться довольно существенным. Двоичное дерево поиска хорошо работает со случайными данными. В наихудшем случае, при поступлении на вход заведомо отсортированных данных, мы получаем вырожденную временную сложность O(N) . Так как в этом случае элементы будут всегда вставляться только в одно поддерево. В итоге мы получим обычный связный список и потеряем все преимущества двоичного поиска.
Как решить данную проблему? Для этого используются сбалансированные деревья, вроде красно-черных деревьев, которые предотвращают подобные ситуации в принципе. Но и сложность реализации повышается. Однако порой эта сложность полностью себя оправдывает.
Теперь приведем реализацию бинарного дерева с операциями вставки нового узла и поиска.
Реализация бинарного дерева на языке С.
Еще раз приведем реализацию структуры, представляющей узел дерева:
typedef struct _Node { int data; struct Node *parent; struct Node *left; struct Node *right; } Node;
typedef struct _Node
int data ;
struct Node * parent ;
struct Node * left ;
struct Node * right ;
} Node ;
Теперь структуру, описывающую само дерево поиска. В структуре будет храниться ссылка на корень дерева и количество узлов в нем.
typedef struct _BinaryTree { Node *root; int size; } BinaryTree;
typedef struct _BinaryTree
Node * root ;
int size ;
} BinaryTree ;
Напишем метод для создания нового дерева, который вернет указатель на созданное дерево.
BinaryTree *createTree() { BinaryTree *tree = (BinaryTree*)malloc(sizeof(BinaryTree)); tree->size = 0; tree->root = NULL; }
BinaryTree * createTree ()
BinaryTree * tree = (BinaryTree * ) malloc (sizeof (BinaryTree ) ) ;
tree -> size = 0 ;
tree -> root = NULL ;
Добавление нового узла.
Теперь реализуем метод для добавления нового элемента в дерево. Если дерево еще пусто(root указывает на NULL ), то создаем корень дерева, если нет, то сравниваем значение, которое должен хранить новый элемент со значением текущего узла. Если оно меньше, то двигаемся в левое поддерево, а если больше — в правое, пока не найдем пустой узел, в который можно будет добавить данные:
//добавление нового узла Node *addNode(BinaryTree *tree, int data) { Node *newNode = (Node*)malloc(sizeof(Node)); newNode->data = data; newNode->left = NULL; newNode->right = NULL; if(tree->root == NULL) { tree->root = newNode; tree->size++; return newNode; }else { Node *currentNode = tree->root; Node *parent; while(true) { parent = currentNode; if(data < currentNode->data) { //идем в левое поддерево currentNode = currentNode->left; //нашли пустой узел? if(currentNode == NULL) { //добавляем сюда новый узел parent->left = newNode; tree->size++; return newNode; } }else { //идем в правое поддерево currentNode = currentNode->right; //нашли пустой узел? if(currentNode == NULL) { //добавляем сюда новый узел parent->right = newNode; tree->size++; return newNode; } } } } }
//добавление нового узла
Node * addNode (BinaryTree * tree , int data )
Node * newNode = (Node * ) malloc (sizeof (Node ) ) ;
newNode -> data = data ;
newNode -> left = NULL ;
newNode -> right = NULL ;
if (tree -> root == NULL )
tree -> root = newNode ;
tree -> size ++ ;
return newNode ;
} else
Node * currentNode = tree -> root ;
Node * parent ;
while (true )
parent = currentNode ;
if (data < currentNode -> data )
//идем в левое поддерево
currentNode = currentNode -> left ;
//нашли пустой узел?
if (currentNode == NULL )
//добавляем сюда новый узел
parent -> left = newNode ;
tree -> size ++ ;
return newNode ;
} else
//идем в правое поддерево
currentNode = currentNode -> right ;
//нашли пустой узел?
if (currentNode == NULL )
//добавляем сюда новый узел
parent -> right = newNode ;
tree -> size ++ ;
return newNode ;
Данный метод возвращает указатель на добавленный узел дерева.
Теперь мы можем создать новое дерево и добавить туда несколько элементов.
BinaryTree *tree = createTree(); printf("%s = %i\n", "Count:", tree->size); addNode(tree, 50); addNode(tree, 10); addNode(tree, 75);
BinaryTree * tree = createTree () ;
printf ("%s = %i\n" , "Count:" , tree -> size ) ;
addNode (tree , 50 ) ;
addNode (tree , 10 ) ;
addNode (tree , 75 ) ;
Поиск узла с заданным ключом.
Поиск узла в двоичном дереве подразумевает перемещение по дереву и сравнение искомого ключа с ключами, которые хранятся в каждом узле. При каждом сравнении возможны три различные ситуации:
1). Значение ключа совпадает со значением в просматриваемом узле. Значит, элемент найден и мы возвращаем указатель на него.
2). Значение ключа меньше, чем значение, которое хранится в текущем узле. Значит, нужно продолжить поиск в левом поддереве. currentNode = currentNode->left .
3). Значение ключа больше, чем значение, которое хранится в текущем узле. Значит, нужно продолжить поиск в правом поддереве. currentNode = currentNode -> right .
Теперь приведем реализацию самой функции поиска. Если элемент найден не будет, то функция вернет значение NULL .
//поиск узла Node *search(BinaryTree *tree, int key) { Node *currentNode = tree->root; while(currentNode->data != key) { if(key < currentNode->data) currentNode = currentNode->left; else currentNode = currentNode->right; if(currentNode == NULL) return NULL; } return currentNode; }
//поиск узла
Node * search (BinaryTree * tree , int key )
Node * currentNode = tree -> root ;
while (currentNode -> data != key )
if (key < currentNode -> data )
currentNode = currentNode -> left ;
else
currentNode = currentNode -> right ;
if (currentNode == NULL )
return NULL ;
return currentNode ;
Обход дерева.
Процедурой обхода дерева называется посещение всех узлов дерева по одному разу в определенном порядке. Существует три разных порядка обхода: прямой , центрированный (симметричный) и обратный. Мы рассмотри здесь реализацию наиболее часто используемой процедуры обхода, а именно симметричного порядка обхода. Реализовав данный тип обхода вы с легкостью реализуете два оставшихся. Центрированный порядок обхода подразумевает посещение сначала двух потомков некоторого узла, а затем самого узла. В итоге он обрабатывает узлы дерева в порядке возрастания. Другие два типа обхода используются в разборе алгебраических выражений.
Так как деревья сами по себе обладают рекурсивной структурой, то и обход мы также выполним с применением рекурсии. Итак, наш алгоритм будет состоять из следующих шагов:
1). Обход левого поддерева.
2). Посещение узла(подразумевает какие-то операции над узлом, в нашем случае это просто вывод значения, хранимого в узле на экран).
3). Обход правого поддерева.
Данный алгоритм очень легко реализуется:
//симметричный обход дерева void inorder(BinaryTree *tree, Node *localRoot) { if(localRoot != NULL) { inorder(tree, localRoot->left); printf("%i -> ", localRoot->data); inorder(tree, localRoot->right); } }
//симметричный обход дерева
void inorder (BinaryTree * tree , Node * localRoot )