Значит hh. Чего ожидать от профессии хедхантера? Ранжирование машинным обучением
Работа не волк, но за ней приходится охотиться. Чтобы облегчить процесс, мы разобрали самые частые заблуждения о поиске работы на нашем сайте. Надеемся, это поможет быстрее найти достойного работодателя!
Миф № 1. Работодатели оставят комментарии к вашему резюме, которые будут видны другим компаниям
Нет, никаких тайных комментариев на сайте не существует, как и черных списков. Есть комментарии внутри одной компании: менеджеры, работающие с вакансиями, могут делать пометки для своих коллег. Но эти комментарии точно никогда не увидит человек из другой организации.
Миф № 2. На 350 тысяч вакансий на сайте претендует 23 млн человек
Эти цифры на главной странице часто сбивают с толку. На самом деле не все 23 млн человек ищут работу одновременно: это все резюме, которые появились на сайте с 2000 года. Чтобы узнать реальную конкуренцию в своей профобласти и в своем городе, загляните на : здесь есть актуальная статистика рынка труда.
Миф № 3. Работодатели не просматривают резюме
Миф № 4. Если скрыть резюме от всех, то компании не смогут получить ваш отклик
Если вы закрыли резюме от работодателей или от конкретной компании, то ни за какие деньги она не сможет получить к нему доступ. Но если вы сперва закрыли резюме от всех, а потом откликнулись на вакансию, то резюме автоматически перейдет в статус «Видно только некоторым компаниям»: доступ к нему получит только та организация, на чьи вакансии вы откликнулись.
Будьте внимательны: в обратном порядке это правило не работает. Если вы сперва откликнулись на вакансию, а потом закрыли резюме от всех, то увидеть ваш отклик компании не смогут.
Миф № 5. Работодатели видят все ваши резюме
Частично это правда: если у вас несколько резюме под разные должности и они видны всем, то через поиск на сайте зарегистрированный работодатель сможет найти любое из них. Однако по умолчанию - например, при отклике - мы показываем только одно резюме, без ссылок на остальные.
Миф № 6. Если в вакансии нет зарплаты, значит, она очень низкая
Скрывать зарплату только из-за того, что она низкая, просто не имеет смысла. В этом случае работодателю пришлось бы обрабатывать сотню резюме от кандидатов, которые точно откажутся от предложения.
Но причин скрывать зарплату у компании может быть несколько:
- не хотят сообщать текущим сотрудникам размер оклада их будущего коллеги;
- они готовы предложить больше, если кандидат окажется очень опытным, и меньше, если ему еще нужно расти;
- не хотят раскрывать размер зарплат компаниям-конкурентам.
Миф № 7. Нет смысла откликаться на старые вакансии
Вовсе нет! Большинство работодателей размещают объявление сроком на один месяц. За этот месяц вакансия успевает уйти далеко вниз в результатах поиска, хоть и остается актуальной. Поэтому последними тремя днями можно не ограничиваться: если вакансия все еще висит на сайте, скорее всего, она еще актуальна.
Я и мои коллеги - рекрутеры в основном пользуемся базовой российской торговой площадкой на рынке труда, — Head Hunter (далее — ХХ). Дорогие соискатели, посмотрите, как ваши объявления смотрятся "с другой стороны экрана". Эти советы помогут не только вам найти работу, но и нам - не упустить потенциальную "золотую рыбку"! Итак, сегодня поговорим о том, как правильно пользоваться сайтом HeadHunter для поиска работы.
Что значит «найти хорошую работу»?
Искать работу — значит продавать свой трудовой ресурс (время, силы, опыт, квалификацию) хорошему работодателю. Чтобы по деньгам было достойно, работа интересная, зарплата стабильная, и по возможности недалеко от дома. А всякая продажа, как известно, начинается с рекламы. Её надо правильно составить и подать, иначе будет как со спамом, который вы каждый день выгребаете из почтового ящика.
Чего проще: напиши резюме, размести на ХХ, подпишись на рассылку новых вакансий, и откликайся. Так можно искать работу годами и только удивляться безразличию работодателей.
Ваша целевая аудитория — менеджер по подбору персонала, чаще всего женщина в возрасте около 30 лет. Её работа: размещать вакансии на ХХ, отслеживать резюме, просеивать (до 90% — в корзину!), а более-менее подходящим звонить. Попробуем привлечь её внимание.
Для начала определите свою позицию на рынке труда.
Сколько соискателей сейчас конкурирует с вами за хорошую работу? И каков спрос, т.е. количество вакансий?
Зайдите на ХХ как работодатель. Просто выберите в верхней строке опцию «Ищу резюме». А дальше введите ключевые слова, например, «секретарь-референт», регион и всё прочее. Интервал укажите «за неделю», там самое актуальное. Вот только желаемый диапазон зарплаты оставьте пустым. Нажимаем кнопку «Найти», и перед вами картина рынка.
Самое важное — в колонке слева. Только что я проделал эту процедуру по запросу «секретарь на ресепшн» по Москве за неделю. И увидел 410 соискателей с 461 резюме. Не так уж много.
Вас, конечно, волнует зарплата. По данной вакансии она выглядит так:
- 15 000-25 000 руб. — 25 чел.
- 25 000-40 000 руб. — 211 чел.
- 40 000-55 000 руб. — 142 чел.
- 55 000-70 000 руб. — 42 чел.
- 70 000-85 000 руб. — 22 чел.
- От 85 000 руб. — 19 чел.
То есть, 77% соискателей хотят зарабатывать от 25 до 55 тыс. руб. Значит, середина рынка труда — где-то около 40-50 тысяч. И если вам особенно нечем хвастаться в плане образования, опыта, знания языков и прочего, — это, скорее всего ваш потолок.
Ниже находим ещё много поучительного. Опыт работы (я сразу буду писать в процентах):
- Более 6 лет — 42%
- 3-6 лет — 33%
- 1-3 года — 25%
- Без опыта — 11%.
Попробуйте во всех этих разделах щёлкнуть по опциям, соответствующим вашим данным. Например, возраст 20-30 лет, опыт 3-6 лет, язык английский и так далее. И тогда в разделе «Зарплата, руб.» вы увидите, на какие деньги можно рассчитывать.
Теперь повторим всё с точки зрения соискателя. Нажмите «ищу вакансии», введите все нужные параметры. В нашем примере вы бы увидели следующее:
Найдено 130 вакансий. Это значит, в целом по Москве среди секретарей сейчас конкурс около 4 человек на место. Можно побороться!
Зарплата:
Указана: 97. Не любят работодатели сразу называть сумму! Предпочитают «по результатам собеседования». Ничего страшного, картинка всё равно понятная:
- От 25 000 руб. — 92 (т.е., всего 5 — ниже!)
- От 35 000 руб. — 73
- От 45 000 руб. — 40
- От 55 000 руб. — 13
- От 65 000 руб. — 10
Сравним эти цифры с зарплатными ожиданиями соискателей. Картина похожая. Только понятно, что на 35-40 тыс. можно рассчитывать, а за зарплату выше 65 тыс. придётся повоевать.
Ваша вывеска
Менеджер по подбору персонала, с которого начнётся ваше знакомство с будущим работодателем, впервые увидит вас на ХХ в кратком формате, в длинном ряду конкурентов-соискателей. Это ключевой момент: будет ваше резюме прочитано, или пропущено, как спам. Так же как уличные вывески: мимо одних вы пройдёте, не глядя, а другие завлекут вас в магазин.
Зайдите на ХХ как работодатель, введите свои параметры и вот что вы увидите:
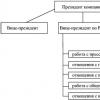
- Фото;
- Название искомой вакансии;
- Опыт работы;
- Ожидания по зарплате;
- Возраст;
- Последнее место работы и продолжительность;
- Сколько ещё резюме у соискателя.
Всё это пишете не вы сами: ХХ автоматически забирает из вашего резюме.
Посмотрите «вывески» ваших конкурентов. Какие из них вас привлекли, а какие вы проскочили не раскрывая? Учитесь на чужих ошибках, следуйте лучшим образцам!
Работодатель игнорирует «вывески», где не заполнен хоть один из разделов:
- Нет фото, — наверное, крокодил.
- Нет зарплаты, — наверное, слишком много хочет.
- Не указан возраст, — наверное, либо 18 (нет опыта), либо за 70 (слишком много опыта).
На ХХ в разделе «поиск резюме» есть даже опции не показывать резюме без фото и указания зарплаты. Так что, спрятав лицо и скромно умолчав о своих ожиданиях, вы можете вообще не попасться на глаза работодателю.
Представьте, что в магазине вы видите надпись «мясо», без товара и без ценника. Ещё краше: «цена по договорённости». Будете вы покупать такой товар?
Не публикуйте фото с паспорта. Сделайте хорошее, привлекательное фото. Улыбнитесь, покажите, что вы — человек, с которым хочется встретиться.
Масса резюме, где лица не видно. Если вы хотите себя показать на стройке, пусть на фото ВЫ в каске на фоне сооружений, а не СООРУЖЕНИЯ, где вы чуть видны.
Не публикуйте «красивых» (как вам кажется) селфи из соцсетей. ХХ — не Инстаграм!
Мужчинам: качок с голым торсом плохо смотрится на вакансию «системный администратор». То же касается охотника на фоне убитого лося (оба примера — из практики).
Дамам: Вы — не на конкурсе фотомоделей. Мы не рассматриваем соискательниц с фотками, где демонстрируются Губки и Бюсты. Иногда Губки — больше Бюстов. Ну, это — смотря, на какую вакансию:).
О деньгах
Проведите маркетинг, как это рассказано в начале статьи. Определитесь с желаемым и разумным диапазоном зарплаты. А теперь прибавьте к нему процентов 20, а если не боитесь, — то и все 30-40. Работодатель никогда не предложит вам больше, чем вы просите, скорее всего, меньше. Так и сойдётесь в цене к общему удовольствию.
На рынке труда, как и на любом другом, важно не продешевить. Если средняя зарплата по данной вакансии — 50 тыс., а вы укажете 30, скорее всего это вызовет подозрение в качестве предлагаемого товара. Или, что совсем нехорошо, работодатель сам с какой-то гнильцой.
Слишком задирать цену тоже не стоит, если только у вас нет каких-то «премиальных» качеств, резко выделяющих вас из ряда других кандидатов. Но эти качества должны быть видны уже на «вывеске». Хороший пример: знание какого-нибудь достаточно редкого, но востребованного языка. Так и надо написать: «Секретарь-референт со знанием хинди и пушту».
Маленькая хитрость: последнее место работы
Вы достаточно долго проработали в солидной брендовой фирме и даже сделали там карьеру. В кризис фирма сократилась, и вы нашли работу в ООО «Ай-яй-яй», откуда вам не терпится уйти. Учтите, что ваш работодатель на «вывеске» увидит именно ООО «Ай-яй-яй», где вы просуществовали 3 месяца. И сделает соответствующие выводы.
Лучше указать как последнее солидное место работы. Если вас вызовут на личное знакомство, не поздно будет признаться в небольшом обмане. Поймут и простят.
Сколько нужно «вывесок»?
У многих соискателей — не одно, а несколько резюме. Когда это стоит делать?
ХХ — ресурс умный. Он выдаёт работодателю не дословные названия резюме, а близко лежащие, в едином семантическом поле. Набрав в поисковой строке «секретарь на ресепшн», я получу ещё резюме «помощник руководителя», «секретарь-референт», «администратор офиса» и так далее. Если ваш диапазон искомых вакансий достаточно узок, не стоит плодить лишние резюме, или указывать все возможные варианты в заголовке. Работодатель всё равно вас увидит.
Другое дело, если ваши возможности широки и разнообразны. Например, вы готовы работать поваром, экономистом, преподавателем китайского и программистом. Бывает и такое! Тогда следует для каждой профессии создать отдельное резюме. Только не ограничивайтесь названием, поменяйте весь текст в соответствии с «вывеской». Но вообще-то рынок труда таких многостаночников не приветствует.
Резюме — ваше предложение работодателю
Про резюме написано столько, что вряд ли можно сказать что-то новое. Но соискатели продолжают повторять одни и те же грубые ошибки. По ним и пройдёмся.
Ошибка 1. Путают резюме с послужным списком или трудовой книжкой. Работодателю интересны не только ваши места работы и должности, главное — что вы умеете делать, каких результатов добились. На этом и надо сосредоточиться.
Ошибка 2 — обратная. Детальное описание трудового опыта, что приводит при достаточном стаже к раздуванию резюме на 10 страниц. Длинных резюме никто не читает. Сократите текст до 2, максимум — 2,5 страниц, оставьте самое главное. То, что нужно работодателю именно на данную вакансию.
Ошибка 3. Стандартная и очень неприятная. Допустим, вы в одной организации постоянно росли в течение нескольких лет. Ни в коем случае не указывайте каждую должность как отдельное место работы! Иначе ваша успешная карьера при поверхностном прочтении превращается в путь неудачника, менявшего работу каждые полгода. Напишите название компании, а под ним — последовательно должности, которые занимали. Особенно если компания несколько раз меняла названия.
Ошибка 4. Долой копипаст! Если вы на разных местах работы занимались примерно одним и тем же, не стоит просто копировать текст несколько раз. Проявите творчество.
Ошибка 5. Обязательно расшифруйте профиль деятельности компании. Рекрутеру ничего не говорит «ООО «Пингвин», если это только не широко известное в отрасли предприятие.
Ошибка 6. Не слишком заморачивайтесь рубрикой «Обо мне». Некоторые соискатели полагают, что это — главное, а на самом деле наоборот. До этой рубрики HR-ы редко доходят. Потому что знают: там будет написано: «Энергичный, обучаемый, стрессоустойчивый, коммуникабельный»… и прочая ерунда. Ещё хуже: «Увлекаюсь йогой, экстремальным альпинизмом, подводной охотой и стрит-рейсингом». Это — точно для Инстаграмма, а не для ХХ. Работодатели ищут работников, а не экзотических экстремалов.
Кстати, находясь в поисках работы, подчистите, хотя бы временно, свои посты в соцсетях. Сейчас многие работодатели поглядывают, что вы там творите. Ваши селфи (особенно это касается дам), а также членство в сообществах, например, в защиту ЛГБТ, — ваше личное дело и гражданское право. Но мимо хорошей работы можете запросто пролететь.
Ошибка 7. Не рассылайте всем работодателям на все вакансии одно и то же резюме! Внимательно прочитайте запрос и подточите своё резюме под него. Только врать не надо: на интервью всё равно расколят.
Ошибка 8. Вывесили резюме и ждём откликов. На ХХ ежедневно появляются тысячи новых резюме. Подождите 2-3 дня, и окажетесь на 5-й странице списка, которую никто не будет читать. Почаще обновляйте резюме!
Добрый совет: учитесь у конкурентов. Так же, как с «вывеской»: найдите с позиции работодателя несколько резюме и оцените, какие вам больше нравятся. И отформатируйте своё в таком же стиле.
Дальнейшие действия
Если вы имеете опыт работы менеджером по продажам, то знаете: скоро только кошки родятся. Минимум 3-6 месяцев, чтобы добиться результата.
Сейчас вы — менеджер по продажам собственного трудового ресурса, скорее всего, не слишком опытный. Надеюсь, что полгода вам ждать результата не придётся, но на моментальный эффект тоже не рассчитывайте.
Главное — не падать духом, не снижать свои претензии на зарплату!
Несколько советов
Вы отправили резюме по приглянувшемуся объявлению. В лучшем случае — звонок и приглашение на интервью, но это — отдельная тема. Скорее всего — ни ответа, ни привета. Ну может быть, пришлют вежливый отказ (в ХХ есть специальная форма).
Почему вам не отвечают? Потому, что многие, получив отказ, начинают звонить, писать, с вопросом: а чем я не подхожу?! Рекрутеры этого очень не любят, поэтому и предпочитают молчать.
Стучаться в дверь, где вам уже не открыли, — типичная ошибка как менеджеров по продажам, так и соискателей. Ни к чему хорошему она не приводит. Представьте: звонок в дверь. Вам предлагают остеклить окна. Вы более-менее вежливо выпроваживаете. Но вам продолжают звонить и выяснять: а почему вы не хотите? А может, всё-таки? Как вы будете себя вести? Тут абсолютно то же самое.
Хорошая американская народная мудрость: лошадь сдохла — слезь.
Удачи, и да прибудет с вами благосклонность Head Hunter!
А если не нравится — ищите работу по знакомствам. Часто это даёт эффект больше, чем ХХ.
Привет, юзернейм! Каждый день мы сталкиваемся с поиском различных данных. Почти на каждом веб-сайте с большим количеством информации сейчас есть поиск. Поиск есть в домашних компьютерах, в мобильных телефонах, в различного рода программном обеспечении. Конечно, если спросить любого разработчика про поиск с точки зрения технологий, на ум сразу придет elasticsearch, lucene или sphinx. Сегодня я хочу заглянуть с тобой «под капот» полнотекстового поиска и разобраться в первом приближении, как же он работает, на примере hh.ru.

Дисклеймер: данная статья не является единственно верной точкой зрения и служит лишь вводной точкой для начального ознакомления с работой текстового поиска и некоторыми вариантами реализации его отдельных частей.
Если посмотреть на детали поиска, то помимо очевидной части в виде поисковой строки можно увидеть еще много чего:
- подсказку (она же suggest),
- счетчик поисковой выдачи (counter),
- различные виды сортировки (sort),
- фасеты (facet) - сгруппированные характеристи документов, например, метро, на котором находится вакансия, также выполняющие функцию фильтров (filters),
- синонимы (synonyms),
- пагинация (pagination),
- сниппет (snippet) - небольшое описание документа в выдаче,

И все это служит для одной цели - удовлетворить потребность пользователя в нахождении нужной информации максимально быстро и релевантно. Например, фильтрация важна, чтобы сузить поисковую выдачу, в нашем случае это может быть фильтр по опыту кандидата, местоположению, или занятости. Фасеты полезны, чтобы отображать, сколько в каждом зарплатном диапазоне находится вакансий. Также важно дополнять запросы и документы синонимами, чтобы по запросу «разработчик java» могли найти документы «java developer».
Помимо самого поиска рядом всегда находится много компонентов, облегчающих жизнь пользователю: опечаточник, отвечающий за исправление ошибок, или саджест, который подсказывает более подходящие запросы, когда вы взаимодействуете со строкой поиска. В некоторых случаях важно уметь переформулировать запрос. Например, часть запроса переместить в фильтры: из запроса «программист москва» Москву можно вынести в фильтр по городу.
1. Базовое
А теперь к делу. Сам поиск делится на две больших стадии:- индексация (обработка документов и раскладывание их по специальным структурам индекса, для того чтобы потом можно было быстро осуществить сам поиск),
- поиск (применение фильтров, булев поиск, ранжирование и т. д.).
1.1. Индексация
Небольшое лирическое отступление. Дальше я введу понятие терма - так принято называть минимальную единицу индексации и запроса. Это та самая единица, которая сохранится в словаре индекса. Это может быть слово, приведенное к его нормальной словоформе или основе, число, емэйл, буквенные n-граммы или что-то еще. Обычно терм включает в себя поле, в котором он индексируется или в котором производится поиск.Для начала входные документы нужно превратить в набор термов и отфильтровать стоп-слова. Ими могут быть как часто встречающиеся слова - предлоги, союзы, междометия, так и другие вещи, например, спецсимволы, по которым мы не хотим искать. Чтобы поиск работал с разными словоформами, в процессе индексации мы обычно приводим все слова к какому-то базовому состоянию. Обычно используется одна из двух процедур: либо стемминг - процесс выделения основы слова (разработка->разработ), либо лемматизация - процесс приведения к нормальной форме слова (навыками->навык).
1.2 Структуры индекса
Самым популярным способом представления индекса является инвертированный индекс (inverted index). По сути это разновидность хэш таблицы, где ключом является терм, а значением список документов (а обычно список id документов, который называется postings list), в котором этот терм присутствует. Обычно инвертированный индекс состоит из двух частей - словаря (term dictionary) и списков документов по каждому терму (posting list):
Кроме того в индексе может содержаться информация о позициях термов в документе (position index), которая будет полезна при поиске термов на определенном расстоянии, в частности при фразовых запросах, о частотности термов, что поможет в ранжировании и при построении плана запроса. Но об этом немного ниже.
1.2.1 Term dictionary
Словарь хранит в себе все термы, которые существуют в индексе, и предназначен для быстрого нахождения ссылки на список документов. Есть несколько вариантов хранения словаря:- Хэш-таблица, где терм - ключ, а значение - ссылка на список документов этого терма.
- Упорядоченный список, по которому можно искать бинарным поиском.
- Префиксное дерево (trie).

Конечно, префиксное дерево может быть не единственной структурой для хранения термов в индексе. Например, рядом может находиться также и суффиксное дерево, которое будет в свою очередь оптимальнее для запросов с джокерами (запросы вида po*sql).
1.2.2 Posting list
Список документов представляет собой упорядоченный список из идентификаторов документов, что позволяет производить с ним некоторые оптимизации. Обычно он хранит в себе не только список документов, в которых встречается терм, но и позиции (postings), на которых оно встретилось. Это решает сразу несколько проблем: мы сразу знаем сколько раз встретилось слово в документе, мы можем делать запросы по фразам и запросы с определенным расстоянием между термами, пересекая сразу несколько списков документов и смотря на позиции термов.
Например в данном списке по терму scala в 6 документе в title слово встречается 4 раза, в позициях 2, 15, 18 и 25.
1.2.3 Документы со множественными полями
В большинстве своем документ состоит из нескольких полей, как минимум из названия документа и его тела. Это помогает при поиске по отдельным частям документа и при коэффициенте значимости терма при ранжировании (например терм встречающийся в названии можно считать более весомым).Плюс ко всему в индексе обычно хранятся не только текстовые поля, но также могут храниться признаки документов, какие-то числовые значения и т. д. Хранение в индексе обычно происходит в виде {поле-терм}.

Например, если взять вакансию, то у нее будет сразу несколько полей: название, описание, компания, зарплатная вилка, город и нужный опыт. Это нужно для того, чтобы пользователь мог удобно искать не только по названию и тексту компании, но также мог отфильтровать по зарплате и опыту, посмотреть, сколько вакансий находится в его городе и в соседних городах, или вообще поискать вакансии определенной компании.
1.3 Сжатие и оптимизации индекса
Для поиска важна скорость работы, поэтому обычно большинство операций поиска по индексу производятся в оперативной памяти. Для этого очень важно применить ряд оптимизаций к индексу, которые позволят уместить его в ограниченный размер памяти. Помимо этого обычно применяется ряд оптимизаций, которые позволяют при поиске перемещаться по индексу с большей скоростью, пропуская его ненужные куски.1.3.1 Компрессия дельтами
Так как мы помним, что список документов по терму (он же postings list) упорядочен, то первая идея, как его сжать, - это сделать вместо списка с id документов список со смещениями id относительно предыдущих. На конкретном списке из 6 идентификаторов это будет выглядеть так:
Таким образом перемещаясь по списку, мы будем всегда вычислять текущий идентификатор из полученного предыдущего значения. Например, ко второму смещению 3 мы добавим первое значение 2 и получим id 5, к третьему 4 мы добавим значение 5, и получим 9 и так далее. При большом количестве документов это очень хорошо работает, особенно в связке с другим способом сжатия - записью чисел формата переменной длины.
1.3.2 VarByte и VarInt
Это способ сохранения каждого отдельного элемента списка в память так, чтобы он занимал минимальное количество места. Например, если первые три смещения влезают всего в 1 байт, то и больше занимать незачем. Учитывая, что наш список содержит не id документов, а дельты - сжатие будет очень эффективным. В таком представлении чисел первый бит каждого байта является флагом, заканчивается ли на этом байте представление текущего числа.
Если первый бит байта 0 - то это последний байт числа, если 1 - нет.
1.3.3 Skip list / Jump table
Список с пропусками - это одна из структур для быстрого перемещения по списку документов определенного терма, пропуская ненужную часть списка. Идея в том, чтобы хранить ссылки на отдаленные элементы списка на диске перед самим списком, т. к. после сжатий мы не можем сказать, где конкретно будет находиться 100 или 200 документ. Например, это удобно, когда есть запрос из двух термов, где один терм будет встречаться часто, а второй наоборот будет встречаться редко, и список документов будет начинаться только с 200-го id документа. Тогда при наличии списка с пропусками для первого списка мы сможем сэкономить время на перемещении и пропустить сразу ненужный блок идентификаторов.
1.4 Запросы
1.4.0 Запрос по терму
Самый простой тип запроса, в котором нам просто требуется найти соответствующий список документов и выдать отсортированные после ранжирования документы.Например так мы найдем список позиций по запросу java :

1.4.1 Булевы запросы (and, or, not)
Булев поиск - одна из самых важных частей в информационном поиске, с которой мы сталкиваемся повсеместно. Весь булев поиск построен на комбинации AND, OR и NOT. Например, когда мы ищем запрос из двух слов: java android , то на самом деле в поиске в простом варианте он преобразуется в java AND android . И это значит, что мы хотим найти все документы, в которых содержатся оба слова.Стоит сразу упомянуть, как происходит перемещение по списку документов. Так как списки документов для каждого терма отсортированы, обычно есть два способа для перемещения по спискам: перемещаться по документам последовательно, проходя их один за одним, или переместиться сразу к определенному документу, пропустив те, которые не нужны (например, когда первый список сильно меньше, и нам не нужно проходить большой блок документов во втором списке). В таком случае мы сначала используем указатель из skip pointers для второго списка, чтобы переместиться максимально близко к нужному id документа, а потом перемещаемся до него линейно.
В момент поиска происходит следующее: в индексе по термам java и android находятся списки документов, затем по ним делается пересечение - то есть мы находим документы, в которых есть оба терма. При таком поиске как раз используются оба способа перемещения по спискам для более быстрого пересечения.

С запросами OR вида java OR scala, где нам нужно найти все документы, содержащие хотя бы один из термов дело обстоит по другому - тут нам не нужно, чтобы терм находился во всех списках документов сразу. Но бывают запросы с несколькими оператором OR, и тогда может встречаться условие минимального количества совпадений, например может быть запрос java OR scala OR cotlin OR clojure с минимум двумя совпадениями, и тогда мы должны показать все документы, в которых встречаются хотя бы два слова из запроса.
В таком случае эффективнее всего работает куча. Мы можем хранить в ней ссылки на итераторы каждого из списка и получать минимальный элемент за константное время. После того как мы берем минимальный элемент, мы удаляем итератор из кучи, делаем шаг вперед и снова добавляем в кучу. Отдельно можно хранить текущего кандидата на добавление в результат и счетчик, сколько раз он встретился, и в тот момент, когда кандидат будет отличаться от минимального элемента в куче, смотреть, проходим ли мы по минимальному количеству совпадений в операции. И либо добавлять в финальный список результата, либо отбрасывать документ.

1.4.2 Префикс/джокеры
Иногда нам хочется найти все документы, в которых встречается слово которое начинается на определенный префикс. В таких случаях нам поможет префикс запрос, который будет выглядеть как jav* . Префиксный запрос очень хорошо работает, когда словарь реализован на префиксном дереве, и тогда мы просто доходим до вложенности префикса и берем все термы, которые лежат ниже.1.4.3 Запросы на фразах и near query
Бывают случаи, когда нужно найти именно фразу целиком, например, “java developer”, или найти слова, между которыми будет не более скольки-то слов, например, “java” и ”developer”, между которыми не более 2 слов, чтобы находились документы, содержащие java android kotlin developer. Для этого дополнительно используются списки позиций слова в каждом документе.
В момент пересечения списков документов происходит все то же самое, как и при операции AND. Но после того, как документ найден в обоих списках, производится дополнительная проверка - то, что термы находятся на нужном расстоянии друг от друга, по разнице позиций (position).
1.4.4 План запроса
Обычно до исполнения самого запроса строится его план. Это происходит для того, чтобы оптимизировать выполнение запроса и чтобы работали такие оптимизации, как список с пропусками для списка документов.Самый простой способ оптимизировать запрос - это выполнять пересечение списков документов в порядке увеличения их размера. Таким образом мы не будем впустую пересекать документы из больших списков, которые отсутствуют в маленьких списках.
Разберем для примера запрос android AND java AND sql . Допустим, что в списке android 10 документов, в sql - 20, а в java - 100. В таком случае лучше всего сначала пересечь наименьшие списки, и оптимизированный запрос будет выглядеть как (android AND sql) AND java .
1.4.5 Расширение запроса - синонимы
Помимо того, что пользователь вводит в поисковую строку, обычно поиск пытается сам расширить запрос, чтобы найти больше релевантных документов. Для расширения поиска может использоваться многое: история запросов пользователя, какие-то персонализированные данные о нем и другое. Но помимо всего этого есть еще и универсальный способ расширения запроса - синонимы.В таком случае при записи документов в индекс терм заменяется на «ссылку» в словарь синонимов:

То же самое происходит при преобразовании запроса. Например, когда мы запрашиваем sales manager , на самом деле запрос выглядит как:

Таким образом в ответе мы получим не только те документы, которые содержат sales manager, но и те, которые содержат sales agent и sales.
1.5 Фильтрация
1.5.1 Fast range filter
Иногда нам хочется фильтровать что-то по диапазону значений, например, по опыту в годах. Допустим, нам хочется найти все вакансии с требуемым опытом от 3 до 11 лет. Первое решение - сделать запрос со всеми вариантами из диапазона, объединив их через OR. Но проблема в том, что значений может быть слишком много. Один из способов решить такую проблему - записывать значение сразу с несколькими точностями:
В данном случае мы будем хранить 5 точностей: год (будем считать это за исходное значение), два, четыре, восемь и шестнадцать.
Тогда при записи будет происходить следующее: например, при записи документа с требованием опыта 6 лет, мы записываем значение сразу во все точности:

При фильтрации «от 3 до 11 лет» происходит следующее: мы выбираем только нужные нам значения в нужных точностях, и получается всего 3 значения вместо 8 и получаем запрос (real value == 3) OR (precision 4 == 4) OR (precision 4 == 8)

1.5.2 Битовые маски
Битовые маски - это неотъемлемая часть индекса. Самое важное использование - это фильтрация удаленных документов. При удалении документа из индекса физическое удаление происходит не сразу. Рядом с индексом записывается специальная структура, где каждый бит означает id документа в индексе, и при удалении возводится бит, а при поиске эти документы фильтруются и не попадают в выдачу.Также можно использовать битовые маски, чтобы выставлять права доступа для каждого пользователя к определенным документам и для кэширования отдельных популярных фильтров. Тогда обычно битовые маски сохраняются отдельно от индекса.
Например, у нас есть популярные фильтры: город Москва, только частичная занятость, без опыта работы. Тогда перед запросом мы можем достать уже сохраненные битовые маски для этих документов, сложить их, и получить финальную битовую маску - какие документы проходят все три этих фильтра, тем самым сэкономив время на фильтрацию.

2. Ранжирование
Как мы помним, главная задача поиска - получение максимально релевантной информации за минимальное время. И в этом нам поможет ранжирование документов после того, как мы отфильтровали документы по текстовому запросу и применили нужные фильтры и права.Самый простой и дешевый способ сделать ранжирование - это просто отсортировать документы по дате. В некоторых системах раньше так и делалось, например, в новостях или в объявлениях недвижимости, так пользователю показывались сначала самые новые документы.
Иногда может использоваться модель ранжирования по количеству найденных слов в документе, например, когда документов не так много, и мы хотим найти все документы, в которых встречается хотя бы одно из слов запроса. В таком случае релевантнее будут те документы, в которых встречаются все слова из запроса или большее их количество.
Конечно, в настоящее время эти способы уже стали неактуальны, и их скорее можно отнести к истории вопроса.
2.1 TF-IDF
TF-IDF (term frequency - inverse document frequency) - одна из самых базовых и самых используемых формул ранжирования. Суть формулы в том, чтобы сделать меньшей значимость терм, используемых повсеместно, например, предлогов и междометий, и сделать более значимыми термы, которые встречаются редко, тем самым показав в выдаче сначала документы с редкими и более значимыми термами из запроса. А теперь давайте разберем формулу на части:TF (term frequency) - это частота встречающегося терма в документе. Подсчитывается она просто:
TF терма `java` = количество терма `java` в документе / количество всех термов в документе
IDF (inverse document frequency)
- инверсия частоты, с которой слово встречается в коллекции документов. Помогает уменьшить вес часто употребляемых слов.
IDF(`java`) = log(число документов в коллекции / число документов в которых встречается терм `java`)
Далее чтобы получить TF-IDF термина java нам нужно просто перемножить полученные значения TF и IDF. Больший вес получат документы, у которых термы встречаются чаще, но при этом они встречаются в меньшем количестве других документов. Это позволяет правильно взвесить запрос, например, слово developer будет встречаться в вакансиях программистов намного чаще, чем название конкретного языка программирования, и при запросе java developer это позволит сделать правильное ранжирование поисковой выдачи.
2.2 Вес поля
Комбинации с весами довольно хорошо помогают, когда в документе есть несколько полей, например заголовок и текст. Тогда мы можем задать больший коэффициент для термов, которые встретились в заголовке документа, и меньший для тех, что нашлись в его теле.2.3 BM25 и BM*
BM25 (Okapi best match 25) является одной из вариаций формулы TF-IDF со свободными весами и нормализацией на средний размер документа. В отдельную формулу выделяют BM25F, которая по сути использует вместо среднего размера документа средний размер конкретного поля (например заголовка или основного текста).2.4 Другие формулы ранжирования
Помимо основных формул ранжирования существуют и другие, например:- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5 Ранжирование машинным обучением
В современном поиске в ранжировании все чаще начинают применять персонализацию, поведение конкретного пользователя, а также асессорские оценки для улучшения результатов выдачи. Не буду вдаваться в подробности работы машинного обучения для задач ранжирования в этой статье, но оставлю для интересующихся данной темой.2.6 Top k документов после ранжирования
Важным моментом в поиске является взятие топа документов или определенной его части, например для пагинации. Основной проблемой является то, что во время ранжирования мы не знаем, сколько всего документов и в каком порядке они стоят.Также мы не можем гарантировать, что весь список документов сможет уместиться в памяти и будет быстро отсортирован. И именно поэтому обычно используются специальные алгоритмы для взятия top k документов.
Один из способов взять топ документов - использовать кучу. Размер кучи всегда k, где k обычно размер страницы * номер нужной страницы . Итерируемся по потоку документов и пускаем все их скоры через heap. При таком способе можно гарантировать сложность n*log(n) и расход памяти k.
Помимо этого можно использовать оптимизации при загрузки не первой страницы топа. Например, если человек переходит на следующую страницу после того, как он уже был на другой странице по этому запросу, например с 10 страницы переходит на 12, то можно запоминать score последнего документа с 10 страницы и все документы с большим значением score сразу отбрасывать. Так можно сэкономить на размере кучи или массива, чтобы не хранить для страницы n - (n*page size) отсортированных документов.
3. Физическое хранение индекса
3.1 Сегменты
Обычно хранение индекса происходит в виде сегментов - небольших самостоятельных индексов. Для записи в таких индексах доступен только один сегмент, последний.В индекс может производиться добавление документов, но удаление из них операция довольно таки тяжелая: чтобы удалить один документ, нужно пройтись по всем спискам документов каждого терма, удалить документ из каждого и изменить их. В общем, задача не из простых. Поэтому удаление производится методом установки специального бита и фильтрацией таких документов битовой маской. Также происходит обновление документа (старая версия документа помечается как удаленная, а новая версия добавляется в конец открытого индекса). Физическое удаление документа из индекса происходит только во время слияния сегментов (merge).
Одним из плюсов нескольких сегментов в индексе является то, что операцию поиска можно делать, проходясь сразу параллельно по всем сегментам индекса:

Но большое количество сегментов не всегда хорошо. При слишком большом количестве сегментов в индексе поисковые запросы могут выполняться дольше, и сам индекс будет занимать больше памяти, чем мог бы, из-за дублирования словаря в каждом сегменте.
3.2 Слияние сегментов (megre)
Существует еще одна важная операция над индексом - слияние сегментов. Основное предназначение данной операции в избавлении индекса от «мусора» - удаленных или старых версий измененных документов. Во время слияния объединяются несколько сегментов, перестраивается их словарь и списки документов, а также происходит физическое удаление неактуальных документов (удаленных или старых версий измененных).
Это может быть дорогостоящей операцией, поэтому существуют стратегии слияний, которые определяют правила, когда нужно и оптимальнее всего их делать. Они могут зависеть от разных факторов:
- процент удаленных документов в индексе,
- количество сегментов на одном уровне (например, при переходе на следующий уровень размер новых сегментов увеличивается в 2 раза),
- время когда можно делать слияние (возможно, в определенное время суток нагрузка на поиск меньше).
4. Поисковый кластер
Когда речь заходит о поиске не на одной машине, а на целом кластере, то одним из вариантов является разделить поиски на базовые и меты. Базовые поиски отвечают непосредственно за поиск по сегментам индекса, а мета-поиски распределяют запрос по базовым (например, если у базовых сделано шардирование или в зависимости от нагрузки и т. д.). И после того, как мета получает результаты от базовых, она сливает их в один итоговый результат, чтобы отдать его пользователю.
4.1 Шардинг и репликация
Шардинг в поиске можно делать как на уровне доменной области (например, в hh есть отдельные индексы для вакансий, резюме и работодателей), так и внутри конкретного индекса. Это позволяет распределить нагрузку между машинами с индексом.Также в поисковых кластерах, как и во всех отказоустойчивых распределенных системах хранения, часто применяется репликация данных. Во-первых, это нужно для ускорения поиска, чтобы можно было отправлять разные запросы на разные базовые поиски. Во-вторых, это делается для избыточности данных, чтобы потеря одной реплики не была проблемой для всего кластера, и поиск мог спокойно считывать данные с других реплик.
4.2 Спекулятивные таймауты
В случае когда реплики нашего индекса хранятся на нескольких базовых поисках, мы можем применять разные стратегии обхода поисков. Можно посылать запросы сразу на несколько базовых поисков, можно дожидаться таймаута от одного и только после этого переходить к следующему.Одной из смешанных стратегий, которая как раз используется в поиске hh, являются спекулятивные таймауты , когда поиск производится последовательно через определенные промежутки времени, чтобы на мета-поиске уложиться в общий таймаут:

5. Бонус трек… или что дальше
Вот мы и посмотрели, как устроен поиск в первом приближении, но осталось еще куча не затронутых тем и тем, в которые можно углубиться. Дальше можно посмотреть, как устроены другие части поиска: как работают кластера, фасеты, статистики, как выделяются сниппеты из целых документов, которые показываются в поисковой выдаче, и как в них работает подсветка искомых термов (highlight), работа с опечатками. Отдельных тем заслуживают саджест поисковой строки, устройство индексации на кластере, другие способы работы описанных уже в статье механизмов, например взятия top k документов.В продолжении изучения темы можно:
- почитать книгу
Михаил Фролкин, Юрий Вировец
HeadHunter - российская компания интернет-рекрутмента , развивающая бизнес в России , Украине , Белоруссии , Казахстане , Литве , Латвии и Эстонии . Крупнейший актив компании - сайт hh.ru. Также HeadHunter владеет сайтом Career.ru и управляет сайтом Работа@Mail.Ru.
История развития
Компания основана в 2000 году. 23 мая был запущен сайт под названием National Job Club, превратившийся впоследствии в HeadHunter.ru, а еще позднее - в hh.ru.
Портал должен был помочь найти профессионалов. Качество соискателей обеспечивалось за счет разграничения прав доступа к резюме, что служило залогом защиты информации. Сайт сделали максимально удобным для работодателей и соискателей. Создатели зарабатывали на продаже базы данных резюме. Портал быстро набирал популярность, и количество соискателей вскоре превысило миллион.
В 2005 году официально начало работу украинское представительство компании - HeadHunter Украина.
В 2006 году состоялись официальные открытия представительств в Новосибирске , Казани , Красноярске , Воронеже , Краснодаре , Самаре , Санкт-Петербурге , Ростове-на-Дону , Екатеринбурге и Казахстане .
В 2007 году группа компаний HeadHunter и фонд прямых инвестиций Digital Sky Technologies приобрели по 20% акций проекта Free-lance.ru .
Также в 2007 году группа компаний HeadHunter приобрела 51% акций работного сайта JobList.ru, принадлежащего компании «Агава» , и запустила совместно с компанией «Агава» проект «100 РАБОТ».
В 2007 году компания HeadHunter присоединилась к ассоциации The Network - международной сети, объединяющей крупнейшие работные сайты в разных странах и позволяющей искать работу за рубежом.
В 2008 году HeadHunter выходит на белорусский рынок, запустив сайт hh.by. В 2010 году на его основе запускаектся совместный проект с порталом TUT.BY - RABOTA.TUT.BY.
В 2011 году в управление HeadHunter переходит проект Работа@Mail.ru.
Деятельность
API
Наилучшее время для размещения резюме - с 9:00 до 13:00. Именно в этот период работодатели наиболее активно просматривают резюме.
Изначально компания HeadHunter занималась только одним сайтом, носившим такое же доменное имя. С 2005года у сайта headhunter.ru появилось короткое доменное имя, которое к настоящему моменту стало основным, а вся компания продолжила называться HeadHunter. В повседневном обиходе сайт hh.ru до сих пор многими называется HeadHunter, что не является ошибкой.
Слухи
Существует слух, что «Паутину профессиональных знакомств» Webby.ru компания HeadHunter за ненадобностью продала за 1 доллар и ящик пива.
В 2011 году компания HeadHunter приобрела 15% аналогичного по функционалу стартап-проекта ITmozg.
В начале 2012 года прошел слух, что HeadHunter готовит к выпуску в конце года новый проект. Официальных подтверждений этого слуха не поступало.
Примечания
См. также
Ссылки
Категории:
- Компании по алфавиту
- Компании, основанные в 2000 году
- Сайты, появившиеся в 2000 году
- Сайты по алфавиту
- Обладатели премии Рунета
Wikimedia Foundation . 2010 .
Смотреть что такое "HeadHunter (компания)" в других словарях:
Род занятий Охотник за головами представитель народности даяков, практикующий охоту за головами членов враждебных племён (Юго Восточная Азия) Охотник за головами (англ. Bounty Hunter) человек, отлавливающий преступников и дезертиров за … Википедия
Mail.ru Group - Российский холдинг, владелец таких проектов, как Mail.ru, ICQ и Одноклассники.ру Холдинг, которому принадлежит интернет портал Mail.ru, социальная сеть Одноклассники.ru , служба мгновенных сообщений ICQ и чуть менее 40 процентов акций социальной… … Энциклопедия ньюсмейкеров
Тип Закрытое акционерное общество Год основания 2003 Расположение … Википедия
Координаты: 57°59′30.46″ с. ш. 56°12′13.53″ в. д. / 57.991794° с. ш. 56.203758° в. д. … Википедия
Официальный логотип La La Land Records La La Land Records американская звукозаписывающая компания, расположенная в городе Бербанк, штат Калифорния. La La Land Records специализируется на саундтреках к кинофильмам и телевизионным сериалам.… … Википедия